
|
| |
 |
Главная » Мануалы 1 2 3 4 5 ... 22 ния при теоретическом пределе 97,8 дБ экспериментальный составляет 106... ПО дБ. Подобная разность объясняется особенностями восприятия слуха и тем, что средний шум квантования значительно меньше принятого в формуле максимального значения. К тому же ФЗЧ, применяемые на выходе квантователя, также снижают этот уровень. В результате можно считать 6п-1-2<: <Db <7. Чем больше динамический диапазон входного сигнала, тем больший числовой уровень квантования нужно применять: Вместе с тем исключение шумов квантования из сигнала нецелесообразно, так как они имеют непосредственную связь с сигналом. При демодуляции из ИКМ-сигнала в аналоговый именно амплитуды шумов квантования позволяют точнее восстановить истинный аналоговый сигнал путем добавления к выборке добавки из амплитуды шума. Таким образом добиваются восстановления истинной амплитуды сигнала. 1.2. ЗАЩИТА ОТ ОШИБОК В ЦИФРОВОЙ СИСТЕМЕ Основные сведения. При обработке, передаче и записи ИКМ-сигнала могут возникнуть ошибки, связанные с режимами работы соответствующих устройств. Ошибки возникают при выпадении как -отдельных символов, так и целых кодовых слов. Кроме того, при хранении или воспроизведении записанной информации возникают помехи, вызванные царапинами или частицами пыли на диске или ленте. Ошибки могут быть как одиночными, так и формироваться в пакеты. Одиночная ошибка вызывает при воспроизведении неправильное восстановление, искажение выходного сигнала, которое субъективно будет восприниматься как щелчок. Искажение (громкость щелчка) зависит от веса искаженного разряда кодового слова. Не все одиночные пропадания импульса заметны на слух. При пропадании импульсов младших разрядов (правая часть 16-битового кодового слова) щелчок практически незаметен. Среднее значение ошибок в таком случае не должно превышать 10 . При выпадении или искажении целых кодовых слов будет наблюдаться искажение самого звукового сигнала. Следовательно, дальнейшие манипуляции с импульсами должны проводиться таким образом, чтобы, если на вновь созданную структуру импульсов будет действовать помеха, которая приведет к искажению либо одного, либо серии импульсов, возможность полного восстановления исходных импульсов была сохранена. Импульсы основного сигнала и добавляемые к ним импульсы или блоки импульсов, подчиняющиеся определенным законам, перераспределяются при передаче или записи ЗС в импульсной форме также по заранее заданному порядку так, чтобы можно было не только обнаружить ошибку, но и исправить ее. При таком кодировании импульс данного мгновения сигнала присутствует при передаче неоднократно -и распределяется таким образом, что при пропадании в одном месте это пропадание обнаруживается, определяется из другого фрагмента и восстанавливается на исходном месте. Распределение же проверочных импульсов, гарантирующих сохранение исходных импульсов в своей комбинации, затем обнаружение и исправление при их пропадании или искажении, а также обнаружение нарушений исходного сигнала проводятся с помощью помехоустойчивого кодирования. Наиболее распространенными кодами, позволяющими проводить обнаружение и исправление ошибок в зависимости от условий, которые могут их создать, являются коды 2RC - двойной код Рида-Соломона с перемежением (CIRC) [9-12], используемые в системе компакт-диск, БЧХ (Боуза-Чоудхури-Хоквинге-ма), применяемого в системе спутникового радиовещания на базе телевизионного канала ([2], а также сверхточные коды в сочетании с 2RC, предлагаемые для использования в системе непосредственного радиовещания [24, 26, 27]. Использование кода CIRC. В соответствии со стандартом МЭК [1] в цифровой системе грамзаписи Компакт-диск для обнаружения, полной и частичной коррекции ошибок используется код CIRC с символами в поле Галуа QF (2). Это двухступенчатый блоковый код со сверточным межблочным перемежением и вну-триблочной перестановкой символов для обеспечения возможности исправления коротких и длинных пакетов ошибок [12]. В обеих ступенях кодирования используется код Рида-Соломона (код RC), в первой ступени (28, 24, 5), а во второй-(32, 28, 5). На рис. 1.4 и 1.5 приведены функциональные схемы кодера и декодера кода CIRC. На вход кодера цифровые данные двух звуковых каналов подаются в виде 16-разрядных слов, разделенных на два символа по восемь бит А я В (соответственно старшие и младшие разряды). В блок данных входят 24 информационных символа (по шесть слов левого и правого каналов). Перед первым кодированием (кодер Q) сначала производится перестановка символа в блоке, при которой слова левого и правого каналов группируются ло три, и эти группы чередуются. Затем осуществляется мел<блочное перемежение четных слов левого и правого каналов с интервалом в два блока. Этими преобразованиями обеспечивается возможность частичного исправления очень длинных выпадений и пакетов ошибок. В кодере Р производится вычисление четырех проверочных символов первой ступени кодирования [9, 12]. Перед вторым кодированием (кодер Р) производится межблочное перемежение символов с постоянным интервалом, равным четырем блокам, которое обеспечивает возможность полного исправления выпадений и пакетов ошибок длиной до 16 блоков. В кодере Р вычисляются проверочные символы второй ступени кодирования. Короткое перемежение символов А длиной всего в 16 *3 03 E? t:; СГ t: N C\3 CNi Cs] cr с £j Cm s s s и Ч £1 & CM CM Cm V T С41 Cm + + + с с C! Й Й 1 CM Cm 1*1 s -51 .Si .si 7- I I I t-, + + + 4 к Cm CM C4J 2j £m Cm Cm =3 § г I CMC Cs] ч:азч;Оз0С10ц^ jT 41- *~ * < - < < < - St <! CSJ CmCmCMCMCMCMCMCm <b I I I r I I I Сч1<1- *C0=Oi-.-,4:)U5Cj,cj, I + + + + ++ + + + + cmcmcsjCmcnjcmcmniCm c5 eg CM C4j § CO S fe § CM CM CM CM cslcslCNiCMCMCMCsj OgCN] I II II II II 11 r смсм ->=&?:г + + S t *й e e e e e с c:, & + + + £1 £j CNJ CM CM C4J JL. в-разрядные аимвалыросуге демодулятора а W12n-m3) , А 1 W2n-n{ll*2) , В 2 W2n.-f-n(2n*3), А Ъ W2ni--12(3B+2), В i VJ12n*S-12{Hl3), А 5 W2n*8-12(5I!+2), В 6 W2n*-1-12(BS*3), А 7 W12n*1-12(7B*2) , В 8 W!2n*5-J2(eiJ+3), А 3 Vll2n*5-12l9n*2), В WW2n-9-12(mil*3), А 11 W2n*9-12(mi+2), В 12 Q!2n-12ll2J]*l) В QJ2n-l-T2(73n) /4 Q12n*2-12(m*l) 15 Q12n*3-t2 (15П) П W12n*2-12(7611+l),A П W12n-2-12(m) , В т W12n*6-12(78D-1), А 19 W12n*B-12(l9I?), в 20W2n*W-12l20n+l), А 21 W12n+m-12(21S) , В 2ZWm*-3-12(221J*l), А 25 W!2n+3-12f23J7) , В 24 W12n*7-12(2tn*l), А 25 \Ы12П*7-П125В) , В 26 Vn2n*ll-12(26dn), А 27 W12n41-72(27B) > В 28 Р12П-12 23 РГ2П + 1 30Р12п^2-72 31 PJZn *3 Задержка. Стадного декодер символа. Зад ерника линии неравной длины декодер ЗаЗер^ка: Sfyx симВоло5 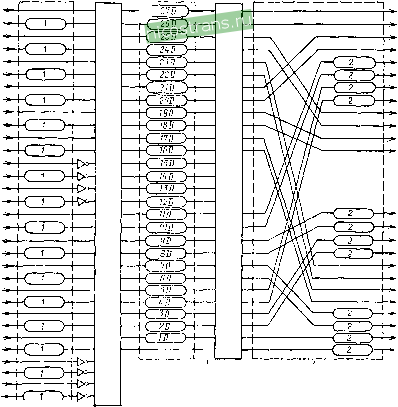 !f§Wi B-pmpntiibii символам на слово МШШВЗ) ,Д W2n-l2(27n*3) ,В. W1Zn.n-12{27Il*3) ,-Wl2n4-12(27B*3) ,S. Vj12n2-lZ(27n*3} ,h WJ2n*2-72l27B+3) ,B . W72n*3-12l27B+3) ,A W72n*3-12(27S*3) ,8. \Ы12пЧ-12(27Л+3),A W12n-7h-72(27B+3],B . W12n5-72l2?Д+3), W2n*5-12[27n+3) ,S . рядныс слова. ПБп Ldn.4 W2nn-12(27ll+3)A-Wl2n*e-Ki27B*3),8. W12n+7-12(27II-3).A-W12n+7-72/27n*3),B. W12n+8-12l27B+3),A W12n*8-12(27Bi-3),8. W2n-9-12[27I/+3)A-W12n+9-12(2711+3), в. W12n*10-12(27B3),h-W12nnO-J2f27Il*3),B. Wr2n+11-72(27Il+3), A ~ W12n+n-J2[27B+3\B. lBn*3 mn*-3 LBn+t H6a+S Рис. 1.5. Функциональная схема декодера CIRC один блок обеспечивает возможность полного исправления кв-ротких пакетов ошибок в первой ступени декодирования. На рис. 1.4 расположение всех символов на выходе кодера соответствует принятому формату блока данных. Проверочные символы Q расположены в середине блока, а проверочные символы Р в конце блока. Все они инвертированы для того, чтобы можно было обнаружить ошибочные блоки, даже если все символы в них ошибочны. В декодере на рис. 1.5 все операции выполняются в обратном порядке, и в соответствии с этим меняются номера ступеней. Сначала производится инвертирование всех проверочных символов, короткое деперемежение символов В длиной в один блок и декодирование кода Cl с проверочными символами Р. Затем производится длинное деперемежение с интервалом в четыре блока и декодирование кода Сг с проверочными символами Q. На выходе декодера осуществляется деперемежение нечетных слов и обратная перестановка символа в пределах блока. В результате восстанавливается исходный порядок слов в блоке с временным сдвигом на 108 блоков. Код RC, входящий в состав кода CIRC, относится как к блоковым, так и к циклическим кодам, поэтому их свойства, методы кодирования и декодирования в равной мере относятся и к нему. Важная отличительная черта кода RC в том, что он является недвоичным [11]. По стандарту МЭК код RC задан в поле Галуа GF (2) с полиномом восьмой степени Р {х)=х^+-х^ + х^ + х' + \ и примитивным элементом поля 00000010 (л;). В обеих ступенях код задается как блоковый с помощью проверочных матриц, приведенных на рис. 1.6. Про-верочные символы вычисляются с использованием следующих равенств: для первой ступени кодирования (код Ci). H,-V, = 0, (1.1) fip = f f 1 f 1 1 ( 1 t 1 1 1 f 1 t f f t t г f f f г ( f f t f f f t 1 1 i 1 1 1 t 1 1 1 t 1 f 1 f 1 1 1 1 1 1 1 1 1 1 1 1 Рис. 1.7. Векторы кодового блока ДЛЯ второй ступени кодирования (код С2) Hp.Vp = 0, (1.2) где Нр,д и Vp,g - векторы-колонки кодового блока на выходах кодеров Р н Q (рис. 1.7). Vv= iii Z.,V/.Z . n,i lt Важнейшие свойства ко- да Рида - Соломона (RC): 1. Является линейным блоковым кодом, поэтому его исправляющая способность полностью определяется минимальным кодовым расстоянием Хэмминга, и это расстояние равно минимальному весу кодового блока. Исправляющая способность такого кода по ошибкам и стираниям определяется известным неравенством 2t + fd, (1.3) где /, / - число ошибочных и стертых символов в блоке, которые исправляются; d - кодовое расстояние. 2. Относится к группе МДР (разделимых кодов с максимальным кодовым расстоянием). Линейный блоковый код является кодом МДР только при условии, что любые (п-k) из колонок проверочной матрицы линейно независимы. Код МДР имеет максимально возможное расстояние
(1.4) где n-k - число проверочных символов в блоке; k - число информационных символов; п - общее число символов в блоке. При четырех проверочных символах в блоке кодовое расстояние равно пяти, и с помощью такого кода могут быть исправлены два ошибочных или четыре стертых символа в блоке. Для кодов МДР полностью известен весовой спектр, который определяется следующим равенством: И = С (V - 1) 2 (- 1) С^ , q--K где со -вес кодового блока, q=2, cod. 20 (1.5) Это позволяет получить точные решения для вероятностей неисправленных ошибочных блоков и символов. Для кодов, не являющихся МДР, такие задачи могут быть решены лишь приближенно. 3. Длина кода RC (в символах) n = q~l. (1.6> Число символов в блоке, принятом по стандарту кода CIRC существенно меньше рассчитанного по данной формуле, поэтому код RC в обеих ступенях укороченный ( 1 = 28 и 2 = 32). Укороченный код RC является также кодом МДР, а его исправляющая способность и спектр определяются формулами (1.3) и (1.5). Для кодов МДР проверочная матрица может -быть разделена на подматрицы, которые также определяют код МДР. Проверочная матрица образуется вычеркиванием одновременно / столбцов и строк первоначальной матрицы при условии, что 1 fn-k, и определяет код МДР, но меньшей длины n=d-f и с меньшим кодовым расстоянием d-d-f, (п-f, k). Это важное свойство позволяет существенно упрощать расчеты вероятностей неисправленных ошибок, когда в декодере одновременно исправляются ошибки и стирания. При таком подходе в зависимости от числа стираний в блоке меняются обнаруживающая и исправляющая способности декодера кода RC. Код CIRC состоит из двух ступеней кодирования и системы перемежения кодовых символов и слов. В первой ступени используется несистематический код RC (28, 24, 5), а во второй - систематический код RC (32, 28, 5). Система перемежения относится к сверточному типу и является неотъемлемой частью кода. Поэтому часто CIRC называют блоковым кодом со сверточной структурой. Исправляющая способность такого кода реализуется лишь при условии, что не нарушается защитный интервал. Это ограничивает допустимые значения средней вероятности ошибочных символов и максимальной частоты ошибок. При нарушении защитного интервала происходит резкое размножение ошибок, которое является одним из существенных недостатков сверточных кодов. В цифровой грамзаписи линейная плотность записи превышает 10 бит/мм, поэтому очень велика вероятность возникновения пакетов и выпадений ошибочных символов и даже блоков. Исходя из этого код построен наиболее оптимальным образом - так, что в первой ступени декодирования может осуществляться полное исправление коротких выпадений длиной до 4... 8 символов (в зависимости от стратегии декодирования). Благодаря длинному деперемежению во второй ступени декодирования могут исправляться выпадения длиной до 7... 16 блоков. При большей длине выпадений в коде CIRC предусматривается возможность частичной коррекции ошибок с помощью интерполяции нулевого, первого и более высоких порядков. Такое исправление возможно лишь при условии, что ошибки обнаружены и, когда их исправить полностью невозможно, стерты. С помощью линейной интерполяции возможно исправление выпадений длиной до 49... ... 51 блока. Стандартом МЭК технические характеристики системы кодирования по исправлению случайных и пакетных ошибок не задаются, так как они в значительной мере определяются стратегией декодирования. Поэтому, говоря о технических характеристиках системы кодирования, следует иметь в виду потенциальные возможности кода, которые совсем не обязательно реализуются. Основные характеристики кода CIRC Длина информационного слова.........16 бит Длина символа.............. 8 бит Длина блока первой ступени кодирования (код Сг) ... 28 символов Длина блока второй ступени кодирования (код Cj) .... 32 символа Число информационных символов в блоке...... 24 Число проверочных символов в блоке . ...... 8 Избыточность кода............. 25% Частота повторения блоков.......... 7,35 кГц Максимальное число ошибок, исправляемое в каждой ступени . 2 Максимальное число стираний, исправляемое в каждой ступени 4 Длительность пакета, исправляемого в первой ступени ... 15 мкс (с защитным интервалом 272 мкс) Максимальная длительность пакета (выпадения), исправляемого во второй ступени декодера.......... 2,04 мс (с защитным интервалом 16,9 мс) Максимальная длительность выпадения, которая частично исправляется с помощью интерполяции......, . 6,7 мс (с защитным интервалом 21,5 мс) Максимальная длительность выпадения, которая частично исправляется с помощью интерполяции нулевого порядка ... 9,8 мс (с защитным интервалом 24,6 мс) Вероятность необнаруженной и неисправленной ошибки . . . 9,7-10 (при Рс(8о) = 10-) Вероятность обнаруженной, но неисправленной ошибки . . 3,53-10- (при Рс(8 ) = 10-). Исправляющая способность кода в отношении случайных независимых ошибок определяется вероятностью необнаруженных и поэтому неисправленных ошибочных символов Рс(ео) и вероятностью обнаруженных, но не исправленных декодером ошибочных символов Рс{ер), моторые могут быть частично исправлены с помощью интерполяции. Эти характеристики обычно рассчитываются для наиболее неблагоприятного случая, когда вероятность ошибочных символов на входе декодера имеет максимально допустимое значение. Стандартом МЭК допускается максимальная вероятность ошибочных блоков З-Ю , что для случайных независимых ошибок соответствует вероятности ошибочных символов Рс(ео) = 10-з. Декодирование кода CIRC. Код Рида - Соломона, входящий в код CIRC, является блоковым, поэтому такие известные методы, как декодирование по минимуму кодового расстояния, декодирование по синдрому и декодирование по максимуму правдоподобия, могут, в принципе, использоваться для обнаружения и ис-22 правления ошибок в этом коде. Они позволяют реализовать потенциальные возможности кода. Однако техническая реализация этих методов с параметрами кода по стандарту компакт-диск практически невозможна из-за неприемлемой для практики сложности и громоздкости декодера. Так как код Рида - Соломона относится к группе недвоичных циклических кодов БЧХ, то могут быть использованы методы декодирования, которые можно разделить на три основные группы: алгебраическое, аналоговое и спектральное декодирование. При алгебраическом декодировании тем или иным способом решается система уравнений синдромов ошибок, и при этом определяются значения ошибок и их локаторы. Если число ошибок не превышает 2-3, то возможны так называемые прямые методы декодирования, при которых вычисления значений ошибок и локаторов производится по определенным формулам или таблицам, находящимся в памяти декодера. При большем числе ошибок система уравнений решается итеративным методом. Это известные алгоритмы Петерсона, Берлекэмпа, Берлекэмпа - Месс и Форни. Аналоговое декодирование осуществляется на основе теории размытых множеств. В последнее время стали использоваться спектральные методы декодирования, основанные на использовании теории дискретного Фурье-преобразования в конечных полях. Аналоговый и спектральный методы сложны в реализации, и использовать их имеет смысл только при необходимости исправления большого числа ошибок в блоке. Так как код CIRC позволяет исправить в каждой ступени не более двух ошибок и четырех стираний, то все известные декодеры этого кода используют алгебраический, в частности прямой, метод декодирования. Алгебраическое декодирование только при исправлении ошибок всегда осуществляется в три этапа: 1) вычисление синдромов ошибок, 2) определение локаторов ошибок (установление числа ошибок в блоке, вычисление коэффициентов многочлена локаторов ошибок, определение корней этого уравнения, расчет локаторов ошибок) и 3) вычисление значений ошибок. На каждом из этих этапов при прямом методе декодирования решаются алгебраические неравенства и уравнения по заранее известным и поэтому запрограммированным формулам. При декодировании код RC обычно задается с помощью проверочной матрицы вида 1 ... 1 1 ............... 1 а/С-) ... а' 1 (1.7) где O/d-2-корни порождающего многочлена. Синдром ошибок вычисляется в матричной форме векторным умножением строк проверочной матрицы Я на транспонированный кодовый вектор V (вектор-столбец) Запись синдрома в алгебраической форме ИЛИ (1.8) (1-9) Sj= Е XiEi, где сог=1Со*г+ег; cu*i - символы принятого блока данных; оц - символы, не имеющие ошибок; ej - ошибочные символы (ошибки); х=а^ - локаторы ошибочных символов; г - число ошибок в блоке. В систему уравнений синдромов ошибок (1.9) неизвестные знчения ошибок и их локаторы входят в виде произведения. Эта система нелинейных уравнений в общем случае может быть решена лишь с использованием искусственных приемов. Одним из методов решения является приведение системы уравнений (1.9) к обобщенному тождеству Ньютона 5;+, -f а, Sj+r-i -f ... -f а, 5 = О (1.10) при о < / < d - 2, где коэффициенты Ог представляют собой элементарные симметрические функции локаторов ошибок (Xj + -f ... +х^), ffg = Х^Х^-- Xl Х. -)- ... -~ r-l г' 0r = (-lf Xl3+-+г (l.ll) Решение вспомогательной системы уравнений (1.10) позволяет определить эти коэффициенты. Важно, что они не зависят от ошибок и определяются только локаторами Хи На втором этапе декодирования определение локаторов ошибок производится с помощью многочлена локаторов ошибок aiz) = zr + Oi- + ...+o (1.12) где 2 -переменная; ш - коэффициенты, определяемые системой уравнений (1.10). Корни этого многочлена при сг(г)=0 связаны с локаторами ошибок равенством 1 2 3 4 5 ... 22 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||